FSHM Weekly-12/01/2025 🔒 RAG-ing Towards Privacy: Personalized Open Source Chatbot 🤖


In the rapidly evolving landscape of artificial intelligence, privacy has become the concern of technological innovation.
This RAG exploration dig into how open source Large Language Models (LLMs) are revolutionizing personalized AI interactions without compromising privacy :
- Local LLM deployments ensure that sensitive information never
leaves your controlled environment - Train models on private datasets
- Maintain strict context boundaries
- Prevent data hallucinations(Piramai)
- Organizations can create tailored AI solutions that respect user privacy
The technology of RAG has seen significant advancements in recent years, with the research in this field following a clear development trajectory.
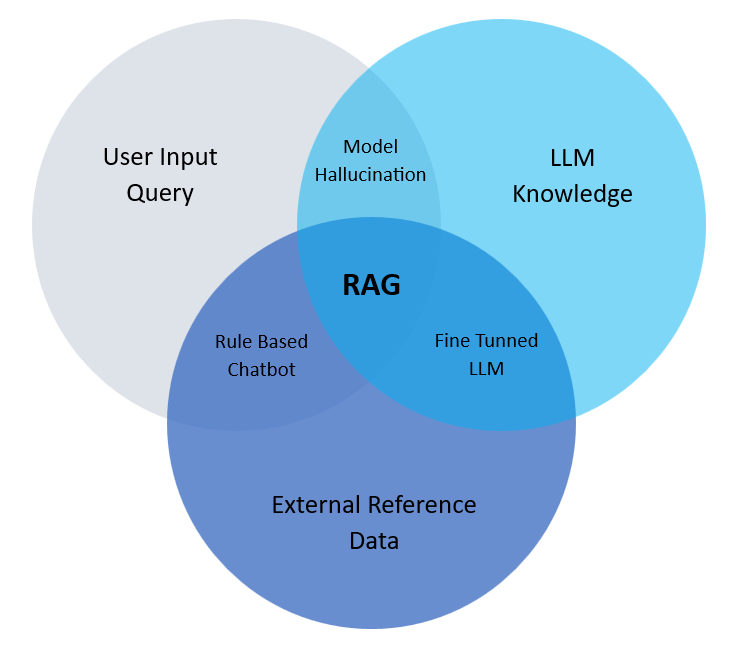
Retrieval-Augmented Generation
RAG combines the strengths of retrieval models, which are adept at accessing vast amounts of external knowledge, with generative models, known for their skill in producing logical and contextually relevant text.
This unique architecture enables RAG to surpass the inherent limitations of individual approaches, opening up new avenues for comprehending and generating natural language. The retrieval mechanism in RAG is crucial as it allows the model to tap into external knowledge sources like databases, websites, or pre-existing corpora.
Core idea = Retriever + Generation
RAG operates on:
-
Retrieval: The model retrieves relevant information from a predefined dataset or document(pdf,doc,..) etc..
-
Generation: Uses the retrieved information to create clear, accurate, and meaningful responses, ensuring the answer is relevant and well-informed.
Various Steps involved in Implementing RAG:
-
Large Corpus Creation: This involves gathering a massive amount of text data relevant to the chatbot's domain. This could include: Articles and manuals related to the topic, Website content and product , Code repositories and technical documentation. The more diverse and comprehensive the data, the better the chatbot will understand the nuances of the domain and provide accurate responses.
-
Chunks Creation: The large corpus is broken down into smaller units of text called chunks. These chunks are typically sentences or paragraphs that contain a single, focused idea. This process helps to
manage the data and made to analyze and understand the meaning of each piece of information. -
Embedding: Each text chunk is then converted into a numerical representation known as an embedding. This embedding captures the semantic meaning of the text, essentially translating the
words into a mathematical code that represents their relationships and context in higher dimension. -
Vector Database (Indexed Embedding): The generated embeddings are stored in a vector database. This database is indexed, like how a search engine indexes web pages. Indexing allows the chatbot to
quickly search and retrieve relevant information based on the user query. -
User Query: The user interacts with the chatbot by asking a question through text input.
-
Similarity and Semantic Search: The chatbot utilizes the indexed vector database to search for embeddings that are similar to the user query. This is done using semantic search algorithms that compare the mathematical representations of the query and the stored information. The goal is to identify the chunks of text that contain the most relevant information to the user's question.
-
Context Injection: The chatbot doesn't just rely on the exact match of the user query. It also injects context into the retrieved information. This context can include: Information about the user (e.g., their location, previous interactions), The current task or conversation flow & Additional knowledge about the domain. By considering context, the chatbot can provide more relevant and nuanced responses that go beyond simply matching keywords.
-
LLM Response: Finally, a large language model (LLM) is used to generate a response to the user query. LLMs are trained on massive amounts of text data and are adept at understanding and generating human-like text. Based on the retrieved information and injected context, the LLM formulates a response that addresses the user's question concisely. This could involve summarizing relevant information, providing instructions, or even generating creative text formats like poems or scripts.
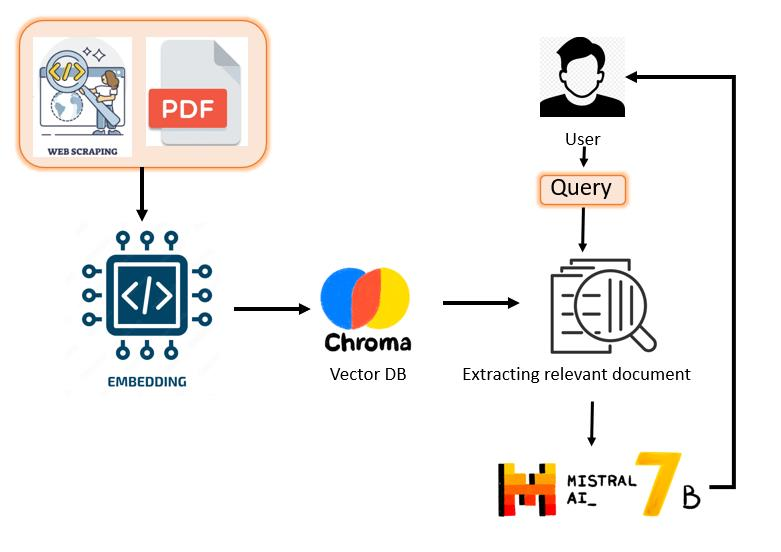
A Guide to Setting Up & Running LLMs Locally and Building GenAI Applications like RAG (Retrieval-Augmented Generation)
Do you want to do experiment with LLM's and make it run on your computer and also use it for building GenAI Applications?
Pre-Requrities for setting up:
- We can also install ollama without Docker, In this setup we are using Docker
- NVIDIA GPU - For GPU use, otherwise we will use CPU
- Python version 3
- Also ensure you have enough disk space of above 15GB and better if 20% of your overall disk space is empty
- git to clone the following repo
git clone https://github.com/Surendiran2003/Local-RAG-LLM.git
Setting Up ollama :
-> cd local_llm/ollama
if you don't have GPU then remove or comment the following lines from docker-compose.yml which reserves resources for GPU
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
- Use
docker-compose up -din the docker-compose.yml you can see the volume path named model where we are mapping our local folder to download models - You can also see we are using docker bridge named genai-network for connectivity between containers or services so that we can bring up out RAG project later.
- Check http://localhost:11434/ your localhost and ensure ollama is running
- use ollama shell for pulling llm's locally follow the cmd
docker exec -it ollama_ollama_1 bash
replace the ollama_ollama_1 with you container name you can see usingdocker-compose ps - In ollama bash using the pull cmd you can pull the models that are available in ollama.
- I am using the following models
ollama pull all-minilman embeddings model
ollama pull mistralan LLM. - Using
ollama listyou can see the models after pulled
Setting Up OpenWebUI
Visit http://localhost:3000/ to access OpenWebUI. It starts with an admin login(dummy), which is stored locally, allowing you to chat with your local LLM models.
Setting Up a Basic RAG GenAI Application
- Navigate to the RAG app directory:
cd local_llm/app- This directory contains
app.py,Dockerfile,requirements.txt, anddocker-compose.yml.
- This directory contains
- Start the RAG app:
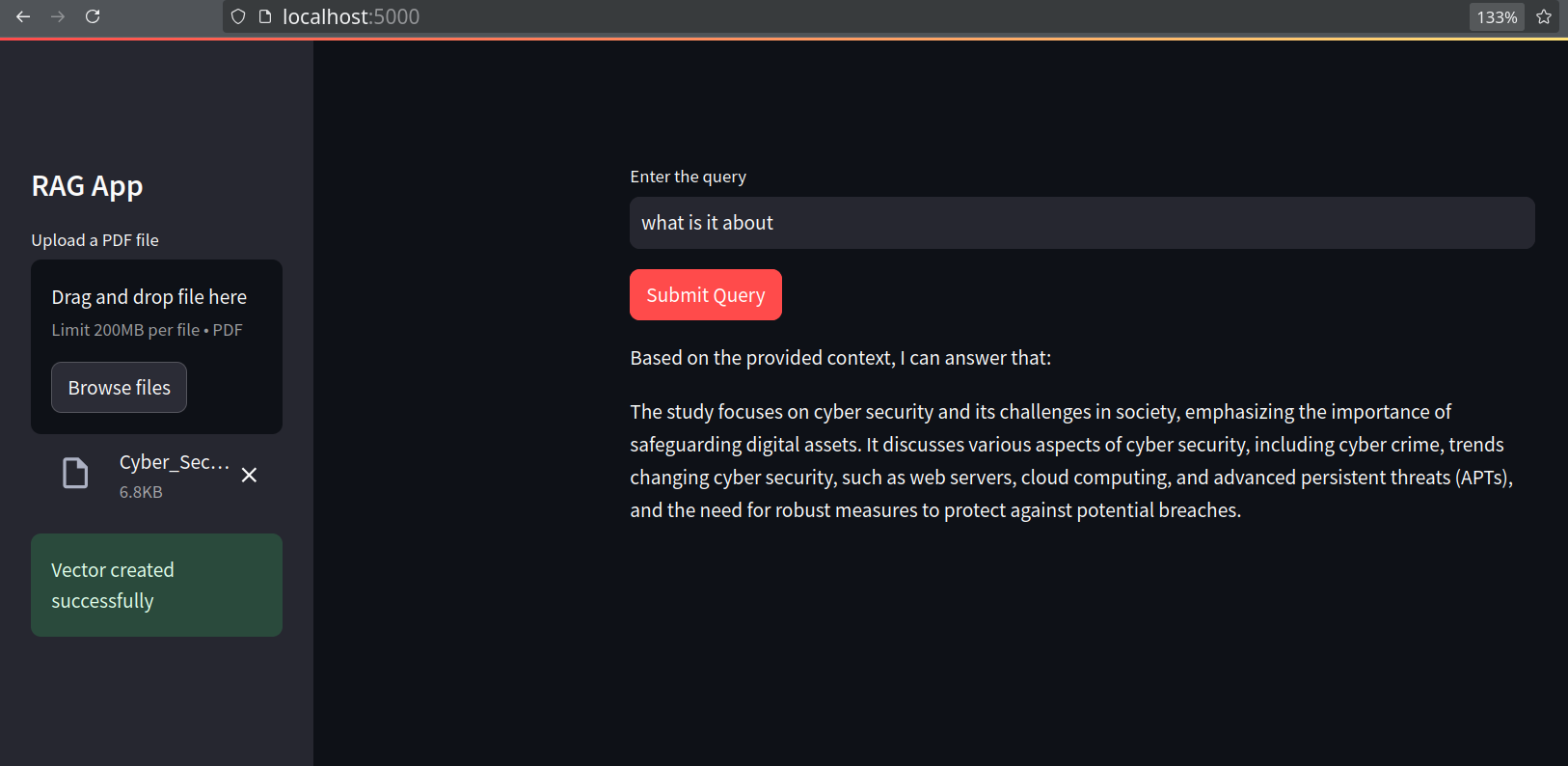
docker-compose up -d - Access the app at:
http://localhost:5000/ - Upload a file and query its content. The app retrieves semantic context from the uploaded PDF, augments the prompt, and the LLM generates the response.
- As AI continues to evolve, privacy-centric approaches like open-source LLMs and RAG offer a promising path forward.
- By leveraging these technologies responsibly, organizations can achieve AI-driven efficiencies while safeguarding user data.